GPU Programming Lecture 01
Parallel Computer Architectures
What is parallelism?
What is concurrency?
Concurrency
Concurrency Two processes A and B are executed concurrently iff the execution of B may start before the termination of A, and vice versa.
Can we have concurrency on a single-core machine?
Under what circumstances is concurrency possible?
- Time multiplexing
- Space multiplexing
Types of Concurrency
→ Time multiplexing
Interleaving Two concurrent processes A and B are executed in an interleaved manner iff A and B are executed alternatingly on the same execution unit.
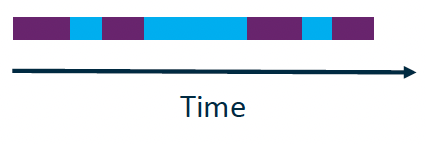
→ Space multiplexing
Parallelism Two concurrent processes A and B are executed in parallel iff A and B are executed simultaneously on different execution units.
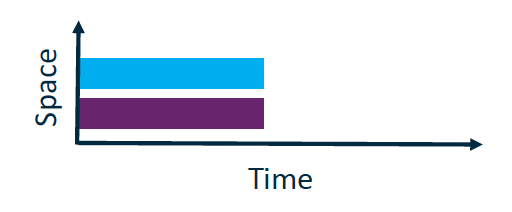
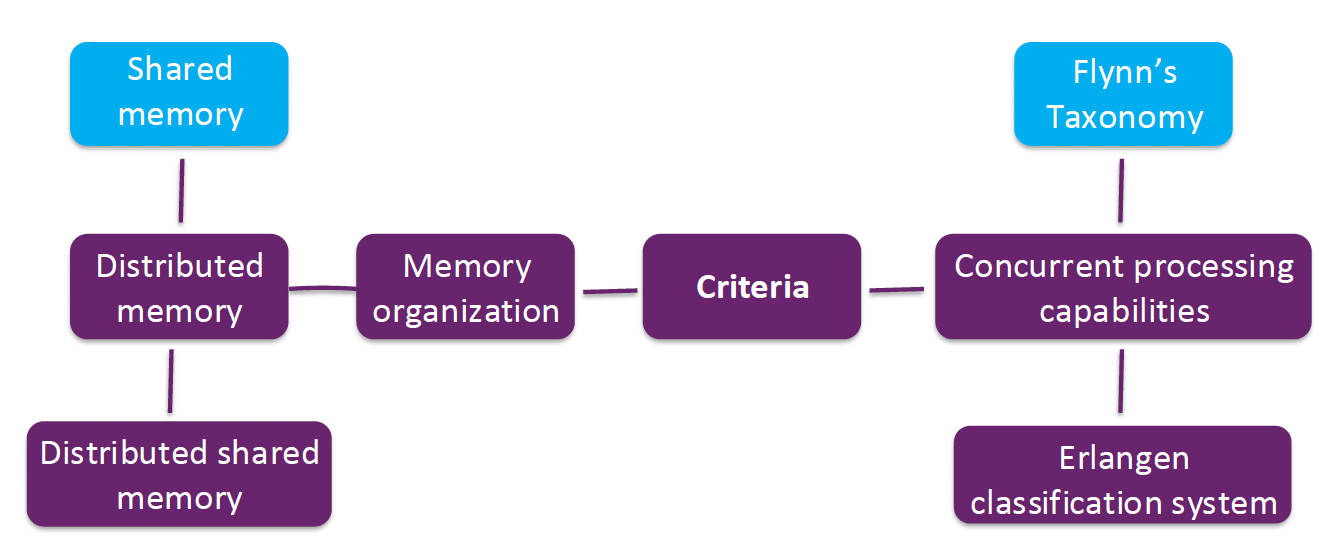
Classification of Parallel Computer Architectures
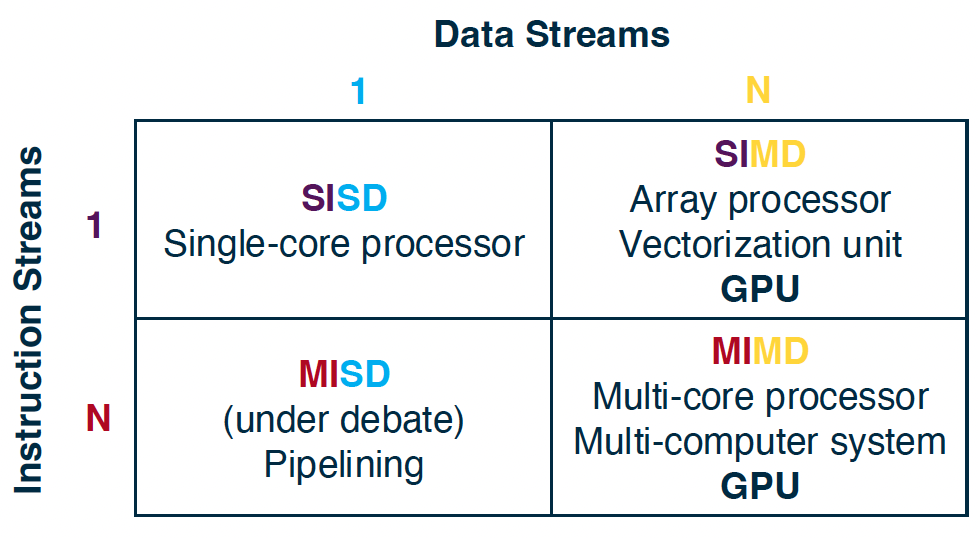
Flynn’s Taxonomy
- Classifies architectures by the multiplicity of interacting data and instruction streams they provide:
- SISD: Single Instruction stream, Single Data stream
- SIMD: Single Instruction stream, Multiple Data streams
- MISD: Multiple Instruction streams, Single Data stream
- MIMD: Multiple Instruction streams, Multiple Data streams
GPU Architecture
Background Information on GPUs
- 1970s Specialized graphics circuits in arcade video game hardware
- 1981 First dedicated GPU chip NEC7220
- 1990s Dissemination of OpenGL for GPU programming
- 2000s (Mis)use of graphics pipeline for matrix computations
- 2008 Nvidia introduces G80, the first general purpose GPU along with CUDA
- 2010s Development and advancement of low-level unified graphics/compute
- Today GPU computing common in AI and HPC applications
- Soon Ubiquitous heterogeneous compute — consumer to HPC
GPU Architecture
- Different GPU vendors, AMD, Intel, Nvidia use different terminology but architectures are similar
- Hierarchy of schedulers
- Memory and cache hierarchy
- Compute units consisting of processing elements

GPU Architecture: Nvidia GA100 (Ampere) Chip
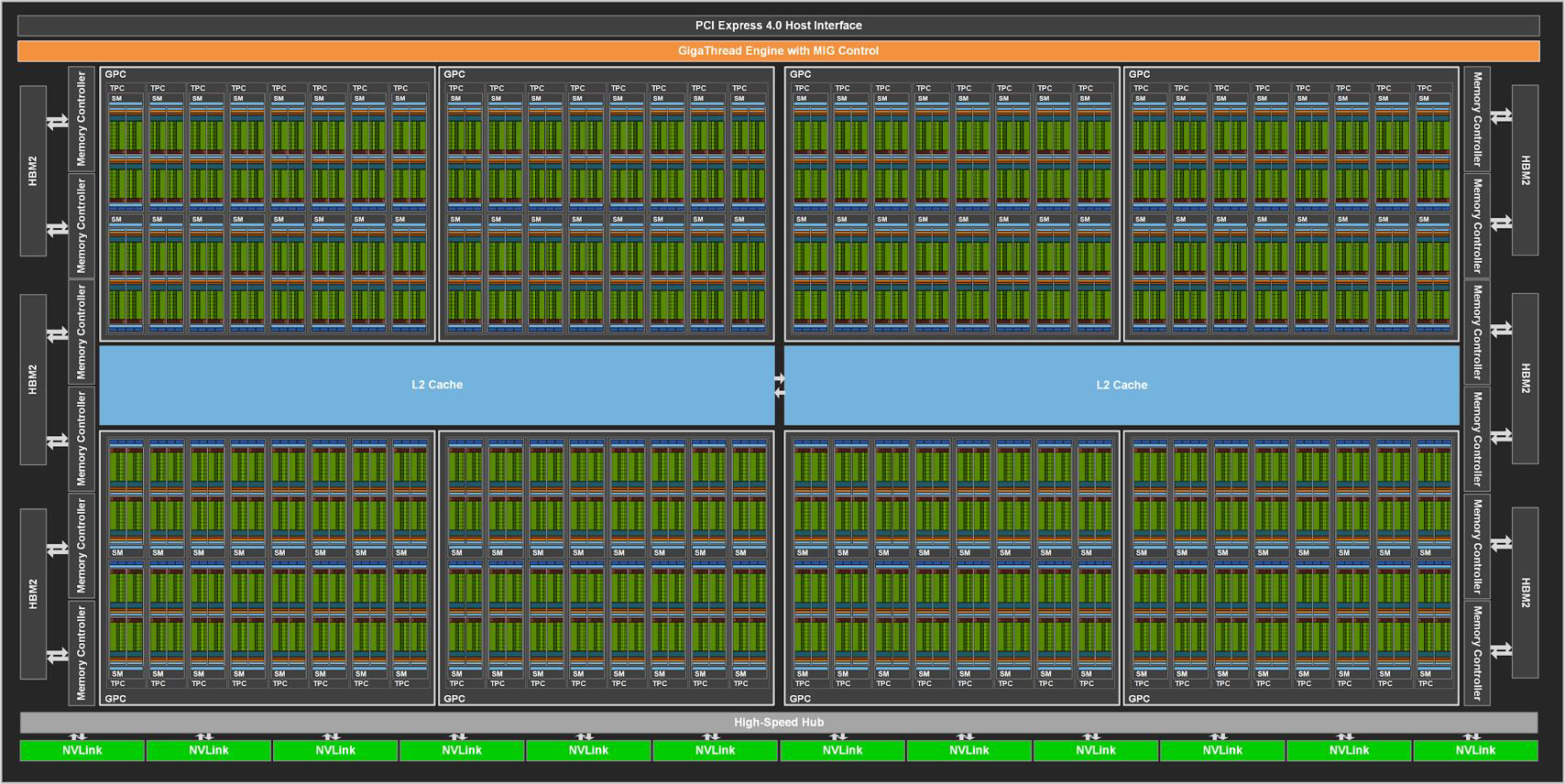
GPU Architecture: Nvidia GA100 SM
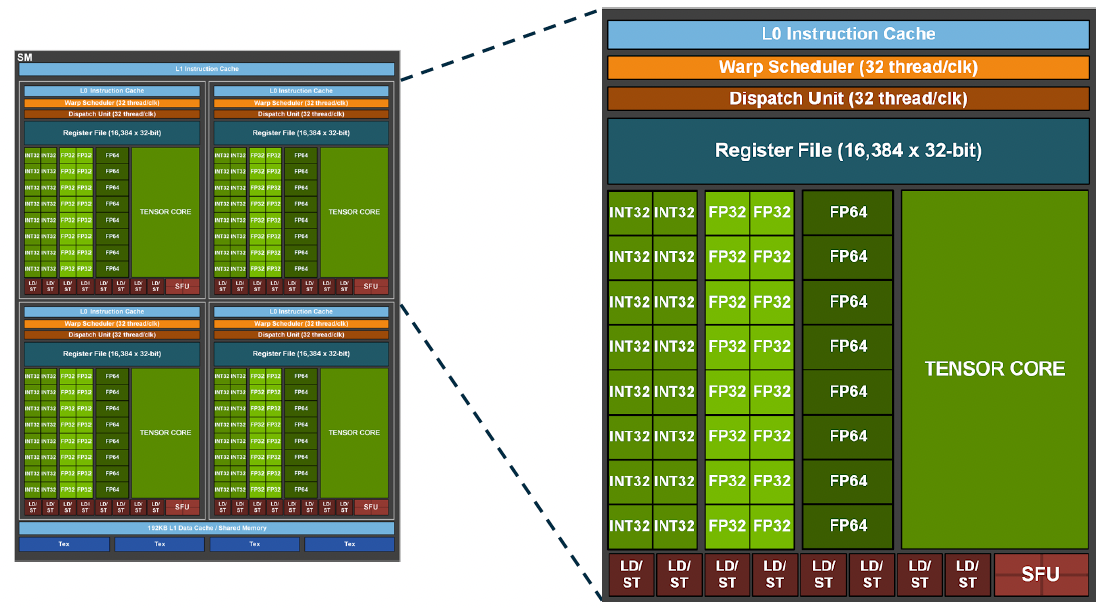
SIMT Execution Model
- Single Instruction, Multiple Thread (Nvidia speak)
- Warp-based execution:
- Warp: group of threads that execute the same instruction on different data elements concurrently
- Lanes in a warp diverge at conditional statements by masking lanes dependent on the execution path they take → SIMD model, but hidden from programmer by the programming model

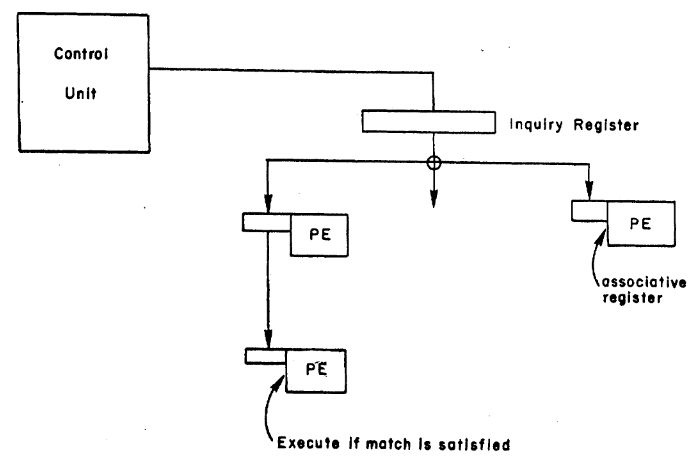
→ GPU is basically the successor of associative array processors
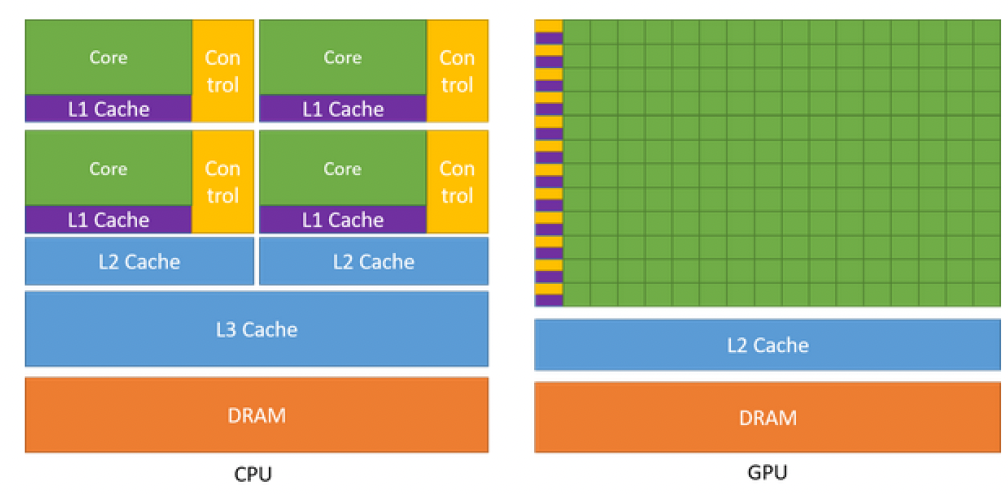
CPU vs. GPU Architectures
CPU vs. GPU Architectures: Compute Density

AMD EPYC 7702 CPU CCD:
- 8 Zen 2 cores (white) and 4 L3 cache slices
- Compute logic (blue) per core including ALU, FPU, SIMD units

AMD MI100:
- 8 arrays (white) à 16 compute units
- Compute logic (blue) per array including ALU, FPU, matrix cores
| CPU | GPU | |
|---|---|---|
| Chip | AMD EPYC 7702 | AMD MI 100 |
| Die size [mm²] | 592 | 750 |
| Cores | 64 | 128 |
| Base Clock [GHz] | 2.0 | 1.0 |
| Instructions per cycle | 16 (2x AVX2 FMA) | 64 (32x FMA) |
| FP64 Peak Performance [GFLOP/s] | 2048 | 8192 |
| Compute density [GFLOP/s/mm²] | 3.46 | 10.9 |
- Compute density of GPUs is (at least) a factor 3 higher since:
- CPUs are optimized for latency → Do one thing as fast as possible.
- GPUs are optimized for throughput → Do as many things as possible at once.
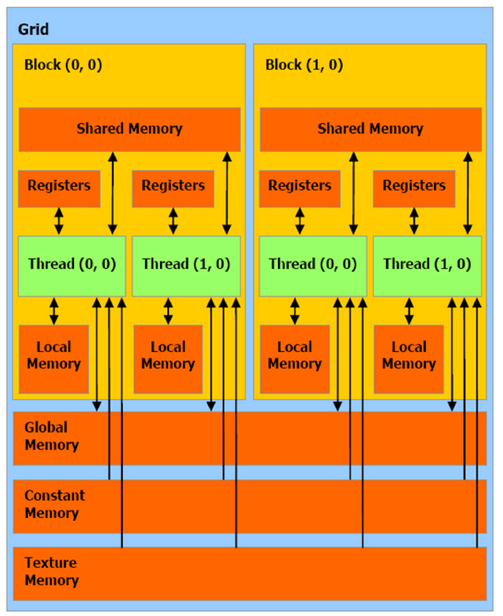
Parallel Programming Models: CUDA
Architecture Model
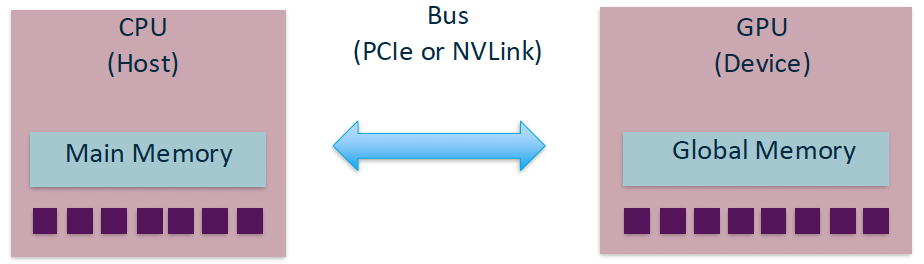
Manual Memory Movement — gedankenexperiment
Let’s consider the impact of data movement on a CPU and GPU:
Doing compute on a CPU:
- We initialise N elements in memory, which takes time $t_A$.
- Then we do some computation, which takes time $t_C N / p$.
Doing compute on a GPU:
- We initialise N elements in memory, which takes time $t_A$.
- Then we transfer to the GPU, which takes $N t_T$.
- Then we compute: $t_C N / P$.
- Then transfer back to main memory, which takes $N t_T$.
Manual Memory Movement Cost
We would like: tA + N tc / p > tA + N tc / P + 2 N tT
Which requires: (p⁻¹ - P⁻¹) > 2 tT / tc
Immediately see:
- Increasing tc improves likelihood GPU computing is worthwhile.
- Reducing transfers between CPU and GPU is a priority.
- If P » p, then only p matters for comparisons.
Execution Model
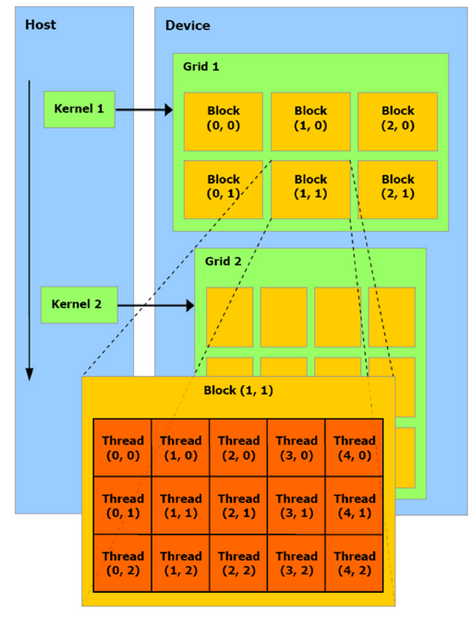
CUDA Workflow
Workflow controlled by master process on host:
- Initialise context
- Allocates host and device memory
- Copy data from host to device
- Configure and execute kernels on device
- Copy data from device to host
- Free memory on device and host
CUDA Kernels
In CUDA,
- Kernel launches are asynchronous, like immediate-mode MPI
- The kernel launch must include size information in the form of
<<<grid, block>>>where grid and block aredim3type. - Kernel qualifiers (e.g.
__global__) determine where the kernel can be called and which returns are allowed (e.g.__global__impliesvoid).
DEMO
Hello World in CUDA
Example: Hello World

DEMO
Vector multiplication in CUDA
Example: Scalar Multiplication
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int main(int argc, char **argv) {
int N = 256;
double *v = new double[N];
double *v_d;
cudaMalloc((void**)&v_d, sizeof(double) * N);
cudaMemcpy(v_d, v, sizeof(double) * N, cudaMemcpyHostToDevice);
scalar_mul<<<1,256>>>(v_d, 5, N);
cudaMemcpy(v, v_d, sizeof(double) * N, cudaMemcpyDeviceToHost);
for (int i = 0; i < N; i++) std::cout << v[i] << "," << "\n";
cudaFree(v_d);
delete[] v;
}
__global__ void scalar_mul(double *v, double a, const int N){
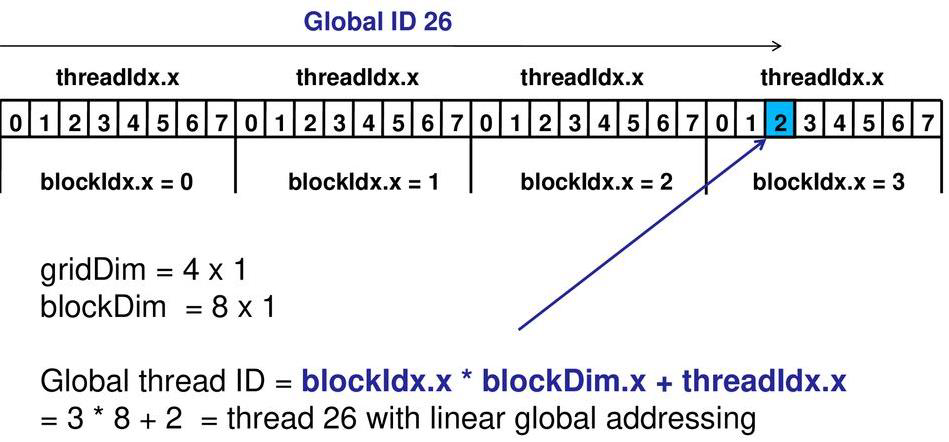
int tid = blockIdx.x * blockDim.x + threadIdx.x;
v[tid] = a * v[tid];
}