HPC Session 01
Session 01 HPC

validates Moore’s law
验证摩尔定律
- Moore’s law is a statement on transistor count/hardware complexity for fixed price
- Moore’s law used to translate directly into performance for decades
- Let’s study performance growth for the biggest machines in the world
计算性能受限于硬件的物理增长,当前硬件的发展更多依赖并行计算能力
免费午餐已结束:单线程性能的提高变得困难,计算性能的提升主要来自并发性
- Increase of performance stems from increase in concurrency
Three classic objectives of HPC/science:
- Throughput & efficiency 吞吐量与效率 Reduce cost as results are available faster; scientists and engineers can do more experiments in a given time frame or study more parameters (UQ)
- Response time 响应时间 Urgent computing as required for tsunami prediction or in medical applications, e.g.; interactive parameter studies (computational steering)
Problem size 问题规模 New insight through never-seen resolution/zoom into scales
- 吞吐量与效率
- 响应时间
- 问题规模
Solution: If chips don’t become faster anymore, we have to squeeze more of them into one computer. 多个芯片 -> 一个计算机中
Implication: If computers become “more parallel”, we have to be able to write “more parallel” codes. 计算机更并行 代码也更加并行
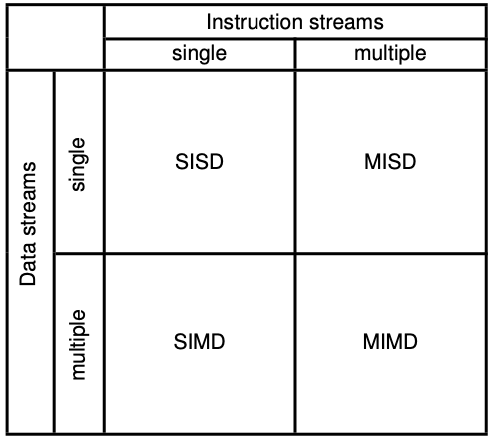
Flynn’s taxonomy 分类法
指令流 & 数据流
Instruction stream: sequence of commands (top-down classification) 上至下
Data stream: sequence of data (left-right classification) 左至右
The combination of data stream and instruction stream yields four combinations: (四种组合)
- SISD
- SIMD
- MISD
- MIMD
SISD
(单指令流,单数据流):传统的单核处理方式
- SISD architecture: One ALU and one activity a time
- Runtime: (2·load +add +store)·N
- Usually load , add , store require multiple cycles (depend both on hardware and environment such as caches; cf. later sessions)
Example: (almost) assembler code in SISD
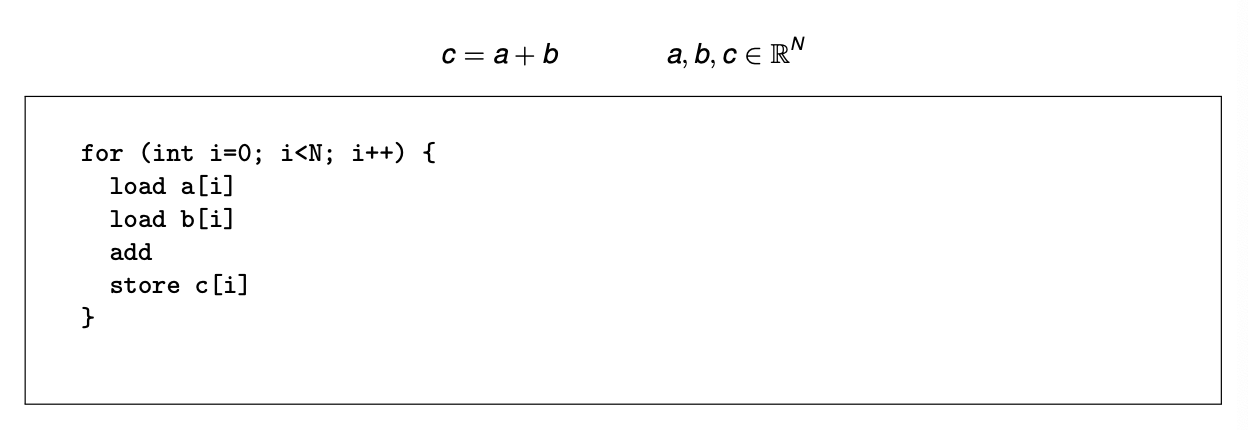
This is the model of a computer most people will typically employ when reasoning about their program – a sequence of operations, completing in order, without the details of data locality or hardware. 顺序完成,不舍己数据局部性或硬件细节
MIMD
Assembler code running on MIMD hardware(汇编代码)
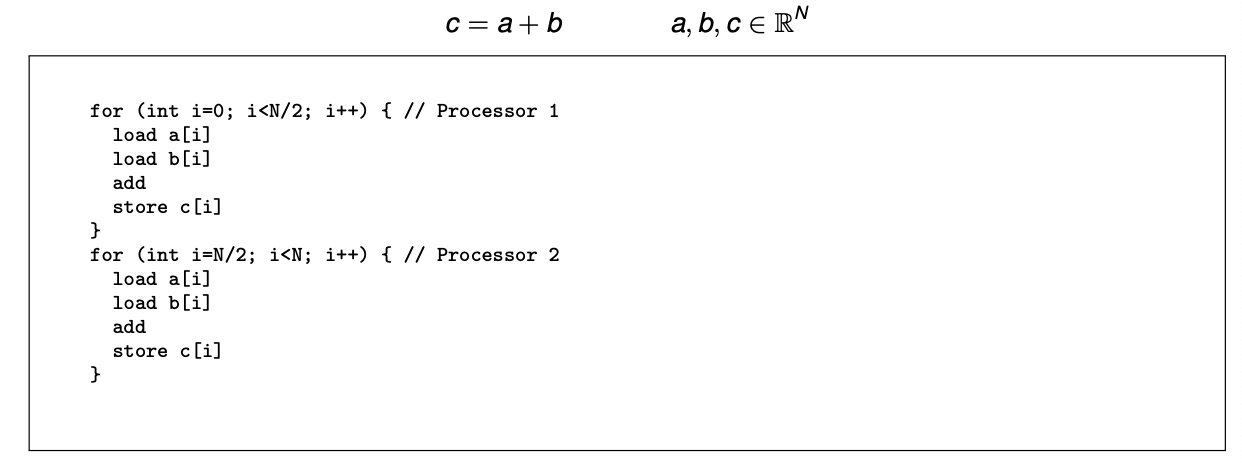
Thus MIMD is frequently thought about as multiple SISD computers working collaboratively on sub-problems. 视作多个SSID协作处理子问题
MIMD remarks
MIMD describes many processors working on their data independently. 独立工作
SPMD – Single Program Multiple Data
- Not a hardware type but a programming paradigm
- All chips run same instruction stream, but they might process different steps at the same time (no sync)
- But: MIMD doesn’t say that we have to run the same program/algorithm everywhere
Classification
- SISD
- von Neumann’s principle 冯诺依曼
- classic single processors with one ALU 单处理器
- one instruction on “one” piece of data a time 一次仅处理一个指令
- MIMD
- classic multicore/parallel computer: multiple SISD 多个SISD
- asynchronous execution of several instruction streams (though it might be copies of the same I program) 多个指令流的异步执行
- they might work on same data space (shared memory), but the processors do not (automatically) synchronise 它们可能在相同的数据空间(共享内存)上工作,但处理器不会(自动)同步
SIMD
- ALU: One activity a time
- Registers: Hold two pieces of data (think of two logical regs) 保存两个数据
- Arithmetics: Update both sets at the same time
- Runtime: (4·load +add +2·store)·N/2
- load, add, store slightly more expensive than in SIMD
- load and store can grab two pieces of data in one rush when they are stored next to each other
Almost assembler code running on SIMD hardware

SIMD operates at a lower level of hardware parallelism than the CPU core – it operates at the level of execution units (ALU & FPU). Likewise, it is frequently preferable to implement SIMD parallelism automatically, using compiler optimization or #pragmas. SIMD 硬件并行 操作级别比CPU低——在执行单元(ALU & FPU)上运行。通常采用 1. 编译器优化 2. #paragmas 来走动实现SIMD并行行
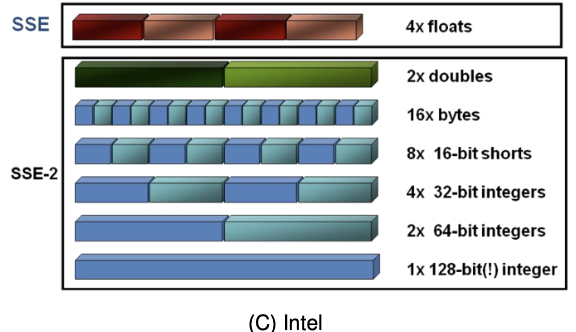
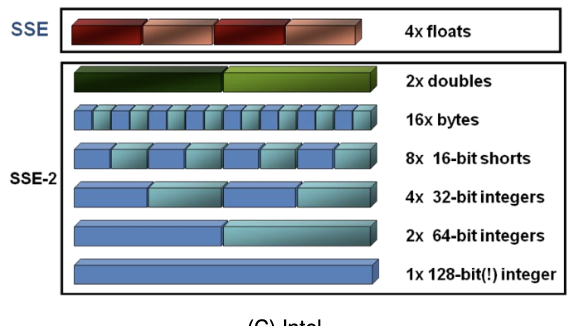
AVX/SSE
Vectorisation: Rewrite implementation to make it work with small/tiny vectors. 矢量化:重写实现以使其适用于小/微型向量。
- Extension to four or eight (single precision) straightforward 扩展 单精度(4-8)
- Technique: Vectorisation/vector computing 矢量计算
- Hardware realisation 硬件实现: Large registers holding multiple (logical) registers
AVX/SSE向量化处理,用于在小型向量上实现并行操作 #没看懂
SSE
- 流式 SIMD 扩展
- SSE = Streaming SIMD Extension
- SIMD instruction instruction set introduced with Pentium III (1999)
- Answer to AMD’s 3DNow (computer games)
- Concept stems from the days when Cray was a big name
- Around 70 single precision instructions 70单精度
- AMD implements SSE starting from Athlong XP (2001)
SSE:流式SIMD扩展,由Intel推出,常用于3D游戏和图形处理
AVX
- Double number of registers 加倍寄存器
- However, multiple cores might share registers (MIC) 多个核心共享寄存器(可能)
- Operations may store results in third register (original operand not overwritten 原操作数不会被覆盖)
- AVX 2–AVX512: Gather and scatter operations and fused multiply-add 操作和融合乘加
Classification
- SISD
- von Neumann’s principle
- classic single processors with one ALU
- one instruction on “one” piece of data a time
- MIMD
- classic multicore/parallel computer: multiple SISD 多个 SISD
- asynchronous execution of several instruction streams (though it might be copies of the same I program) 多个指令流的异步执行
- they might work on same data space (shared memory), but the processors do not (automatically) synchronise可能在相同的数据空间
- SIMD
- synchronous execution of one single instruction 同步执行一个单一指令
- vector computer: (tiny) vectors 矢量
- MISD
- pipelining (we ignore it here)
Flynn’s taxonomy: lessons learned/insights 弗林的分类法
- All three paradigms are often combined (see Haswell above) 经常结合
- There is more than one flavour of hardware parallelism 多种硬件并行性
- There is more than one parallelisation approach 并行方法
- MIMD substypes:
- shared vs. distributed memory 共享/分布
- races vs. data inconsistency # ?数据不一致
- synchronisation vs. explicit data exchange 同步 vs. 显式数据交换
Speedup and efficiency
We are usually interested in two metrics(指标):
Speedup: Let t(1) be the time used by one processor. t(p) is the time required by p processors. t(p)是p个处理器所需的时间 The speedup is 加速比公式 \(S(p) = \frac {t(1)}{t(p)}\)
Efficiency: The efficiency of a parallel application is消费比公式 \(E(p) =\frac{S(p)}{p}\)
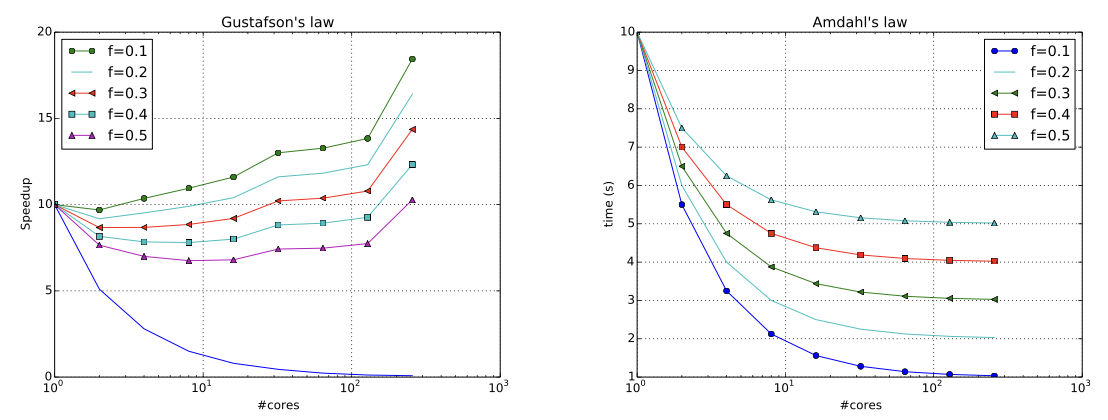
Amdahl’s Law
\[t(p)=f\cdot t(1)+(1-f)\frac{t(1)}p\]Ideas:
- Focus on simplest model, i.e. neglect overheads, memory, (忽略开销、内存) . . .
- Assume that code splits up into two parts:
- something that has to run serially (f) 必须按顺序运行的内容
- with a remaining code that scales 可扩展
- Assume that we know how long it takes to run the problem on one core.
- Assume that the problem remains the same but the number of cores is scaled up 问题相同,但核心数量增加
Remarks:
- We do not change anything about the setup when we go from one to multiple nodes. This is called strong scaling强扩展.
- The speedup then derives directly from the formula.
- In real world, there is some concurrency overhead (often scaling with p) that is neglected here. 并发开销被忽略
Speedup and efficiency—Strong Scaling
Speedup: Let t(1) be the time used by one processor. t(p) is the time required by p processors. The speedup is S(p) = t(1)/t(p). {: .prompt-tip }
- What is the scaling of the speedup if f = 0? 加速比的缩放是多少
- Are speedups smaller than 1 possible?
- What is super linear speed up? 什么是超线性加速? # ???
Efficiency: The efficiency of a parallel application isE(p)=S(p)/p.
- What is an upper bound for the efficiency? 上限
- What is a lower bound for the efficiency? 下限
Strong Scaling – intuition
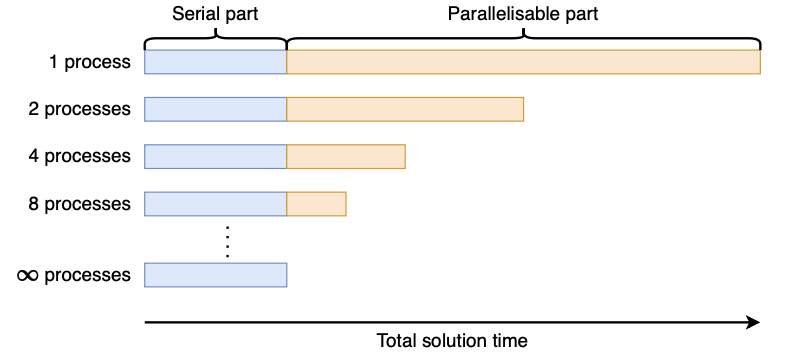
- Given f as the serial fraction, and$t(p)=t(1)(1+\frac{1-f}p)$
- Then $S(p)=1/(f+(1-f)/p)$
- The speedup is limited by the serial fraction: $\lim_{p\to\infty}S(p)=1/f$
- Want to maintain a parallel efficiency of 80% – how does the parallel fraction of the code need to scale as we add more processors? 想要保持 80%的并行效率-随着我们增加更多处理器,代码的并行分数需要如何扩展?
Gustafson’s Law
\[t(1)=f\cdot t(p)+(1-f)t(p)\cdot p\]Ideas: (几乎与Amdahl’s Law相同)
- Focus on simplest model, i.e. neglect overheads, memory 专注最简单模型,忽略开销 内存
- Assume that code splits up into two parts (cf. BSP with arbitary cardinality): something that has to run serially (f ) and the remaining code that scales.
- Assume that we know how long it takes to run the problem on p ranks.
- Derive the time required if we used only a single rank.
Remarks:
- Single node might not be able to handle problem and we assume that original problem is chosen such that whole machine is exploited, i.e. problem size is scaled. This is called weak scaling.
- The speedup then derives directly from the formula.
- In real world, there is some concurrency overhead (often scaling with p) that is neglected here.
Weak Scaling – intuition
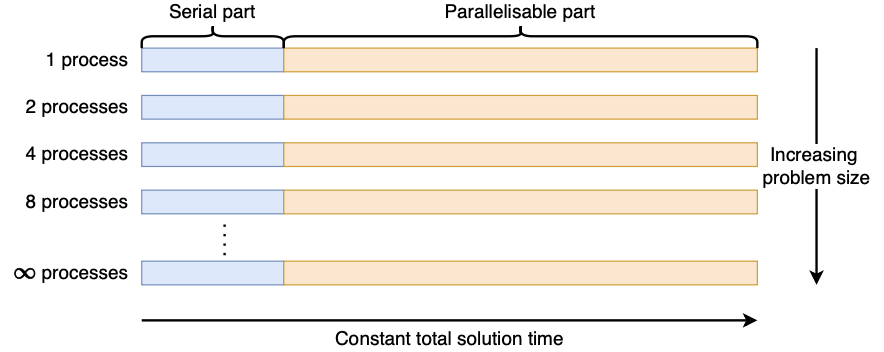
- Perfect weak scaling matches the number of processes to the amount of work to do – giving a constant run time rather than shorter with more processors 提供恒定的运行时间
- Given, $t(1)=t(p)f+p(1-f)t(p)$, then $S(p)=f+(1-f)p$
- What is the efficiency as $\lim_{p\to\infty}E(p)?\lim_{p\to1}E(p)$?
Python Exercise
Disclaimer免责声明: We will typically not be using Python!
Python exercise: Comparison of the speedup laws
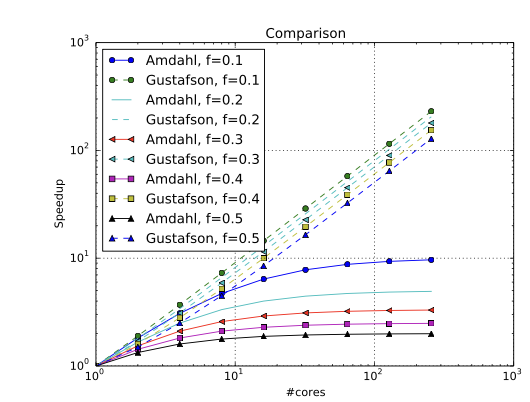
- It depends on whether you fix the problem size.
- It is crucial重要 to clarify assumptions a priori.
- It is important to be aware of shortcomings 意识到缺点.
Shortcomings of simple performance models
- These are very simple performance models with a number of assumptions.
- That a program can be split into two separate parts which can be treated independently.
- That changing a program to run in parallel will not affect the serial part.
- That there is no communication overhead, or parallel management which scales with p.
- That every processor in p is precisely the same, and experiencing the same environment.
- Frequently, real programs will change behaviour significantly when made parallel on the same hardware – e.g., due to frequency scaling or cache effects. 当在相同的硬件上并行运行时,真实的程序的行为会发生显著变化 - 例如,由于频率缩放或缓存效应。
- Computers are much more than a collection of loose CPU cores!
- Phone SoCs are a great example of heterogeneity and ‘the other parts’ leading to dramatically improved performance.
- Is time the most relevant metric anymore?
- Some problems simply react differently to parallelisation!
What about parallel search? If you and p friends need to find a phone number in a phone book (before your time!), does Amdahl’s law give us a reasonable model for the time to find the number t(p) given a known t(1)?
You have a problem. . . How do you parallelize it? 如何并行运行呢?
Typically in HPC, we have a problem which is well-specified (e.g. in a serial program串行) but the current approach is insufficient for some reason:
- Serial is too slow; we need a fast solution 太慢
- Problem is too small; Need to solve a larger or more accurate version # Q 问题太小了;需要解决一个更大或更准确的版本
- Solution is inefficient; we need it solved more efficiently 效率低
There are typically three approaches to applying parallel computing to the serial problem (not mutually exclusive):
- Better align with existing hardware capabilities (e.g., SIMD, caches) 更好地与现有硬件能力对齐
- Split the computation so that multiple cores can work on subproblems 分割后计算 多核处理子问题
- Split the data so that multiple machines can be used to solve parts of the problem simultaneously (distributed memory parallelism) 数据进行分割 多台机器解决 (分布式内存并行)
Programming techniques
Programming Techniques: For each parallelisation paradigm, there are many programming techniques/patterns/paradigms. 对于每种并行化范式,都有许多编程技术/模式/范式。
- We will more or less ignore the competition approach. 忽略竞争方式
- Competitive parallelism is mostly relevant for GUIs and games, where responsiveness to user action is paramount.竞争性并行主要适用于 GUI 和游戏,对用户操作的响应至关重要。
- Cooperative parallelism is useful for solving large compute-bound problems without interactivity.
- These are not necessarily antagonistic concepts: Muller, et al., Competitive Parallelism: Getting Your Priorities Right; https://www.cs.cmu.edu/~rwh/papers/priorities/paper.pdf
- We will today quickly run through three important patterns. 三种模式
- More patterns will arise throughout the course.
Technique 1: BSP
BSP: Bulk-synchronous parallelism is a type of coarsegrain parallelism where inter- processor communication follows the discipline of strict barrier synchronization. Depending on the context, BSP can be regarded as a computation model for the de- sign and analysis of parallel algorithms, or a programming model for the development of parallel software. 一种粗粒度并行性的类型,其中处理器间通信遵循严格的屏障同步学规则。根据上下文,BSP 可以被视为并行算法设计和分析的计算模型,或者是并行软件开发的编程模型。
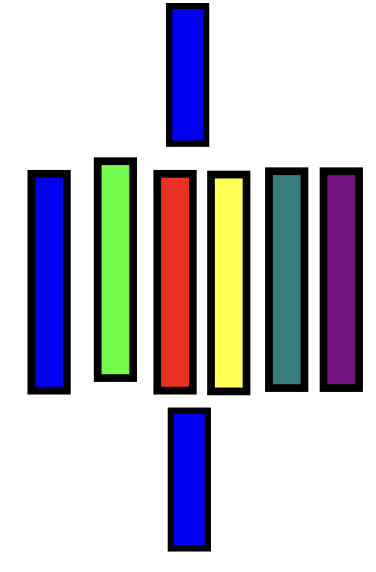
Remarks:
- Other name: Fork-join model
- No communication in original model 无通信
- Superstep
Terminology: 术语
- Bulk # Q 批量
- Fork # Q
- Join/Barrier/Barrier synchronisation
- Grain size (how many subproblems per thread) 颗粒大小(每个线程的子问题数量)
- Superstep
Analysis:
- Parallel fraction f
- Max. concurrency 最大并发
- Fit to strong and weak scaling 适应强弱扩展
Technique 2: SPMD
SPMD: Single program multiple data is a type of coarsegrain parallelism where every single compute unit runs exactly the same application (though usually on different data). The may communicate with each other at any time. Depending on the context, SPMD can be regarded as a computation model for the design and analysis of parallel algorithms, or a programming model for the development of parallel software. 一种粗粒度并行性的类型,其中每个单独的计算单元运行完全相同的应用程序(尽管通常在不同的数据上)。它们可以随时彼此通信。根据上下文,SPMD 可以被视为并行算法设计和分析的计算模型,或者是并行软件开发的编程模型。
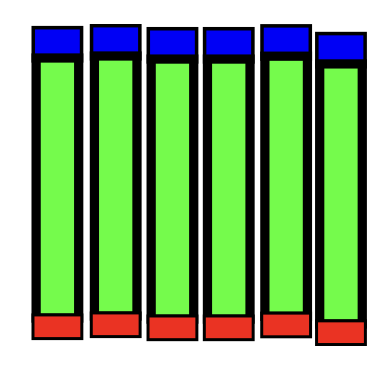
Technique 3: Pipelining
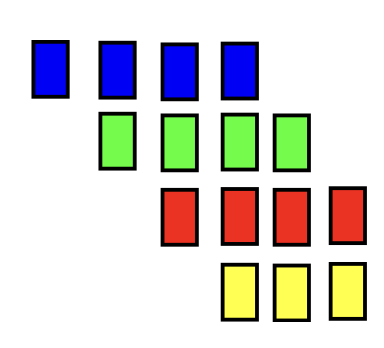
Functional decomposition does not yield parallelism on its own, but …
Pipelining: In computing, a pipeline is a set of data processing elements connected in series, where the output of one element is the input of the next one. The elements of a pipeline are often executed in parallel. 流水线:在计算中,流水线是一组连接在一系列中的数据处理元素,其中一个元素的输出是下一个元素的输入。流水线的元素通常是并行执行的。
Applications:
- Assembly line 流水线
- Graphics pipeline 图形管线
- Instruction pipeline (inside chip) / RISC pipeline 指令流水线(芯片内部)/ RISC 流水线
- Now coming back into fashion (PyTorch, Gpipe; Huang et al) for large ML model training 大型机器学习
Summary, outlook & homework
Concepts discussed:
- Motivation of parallel programming through hardware constraints
- Course structure
- Parallel Scaling laws – Amdahl & Gustafson
- Basics of parallelisation strategies
Next:
- OpenMP!
- OpenMp(2/3)