HPC Session 05 MPI—basics and blocking P2P communication
MPI—basics and blocking P2P communication
MPI 是进程 (process) 级并行,process 间内存不共享,与线程 (thread) 级并行不同
https://mpitutorial.com/tutorials/
https://scc.ustc.edu.cn/_upload/article/files/e0/98/a9f0c4964abdb3281233d7943f9e/W020121113517561886972.pdf
https://blog.zcy.moe/blog/mpi-reference/
Starting point
- Shared memory programming:
- Multiple threads can access each other’s data
- Linux/OS terminology: one process with multiple tasks
- Distributed memory programming:
- Different machines connected through a network or
- one (multicore) computer running several processes, as processes do not share memory or - combinations
De-facto standard for distributed memory programming: message passing (MP- = message passing interface)
- Message passing:
- works on all/most architectural variants, i.e. is most general
- (though perhaps slower than OpenMP, e.g.)
- requires additional coding, as we have to insert send and receive commands
- orthogonal to other approaches, in particular to OpenMP (merger called MPI+X or hybrid)
Historic remarks on MPI
- MPI = Message Passing Interface
Prescribes a set of functions, and there are several implementations (IBM, Intel, mpich, . . . )
- Kicked-off 1992–94
- Open consortium (www.mcs.anl.gov/mpi)
Mature and supported on many platforms (de-facto standard)
- Alive:
- Extended by one-sided communication (which does not really fit to name)
- C++ extension dropped due to lack of users
Huge or small:
Around 125 functions specified
Most applications use only around six
A first MP- application
1
2
3
4
5
6
7
8
#include <mpi.h>
#include <stdio.h>
int main( int argc, char** argv ) {
MPI_Init( &argc, &argv );
printf("Hello world!\n");
MPI_Finalize();
return 0;
}
1
2
mpicc -O3 myfile.cpp
mpirun -np 4 ./a.out
- Use
mpiccwhich is a wrapper around your compiler - Use
mpirunto start application on all computers (SPMD) Exact usage of
mpirundiffers from machine to machine- MPI functions become available through one header
mpi.h使用头文件引入 - MPI applications are ran in parallel (mpi processes are called ranks to distinguish them from OS processes)
- MPI code requires explicit显式 initialisation and shutdown
- MPI functions always start with a prefix
MPI_and then one uppercase letter - MPI realises all return values via pointers 通过指针实现所有返回值
- MPI’s initialisation is the first thing to do and also initialises
argcandargv
MPI terminology and environment
Rank: MPI abstracts from processes/threads and calls each SPMD instance a rank. The total number of ranks is given by size.
1
2
3
4
5
6
7
8
#include <mpi.h>
int main( int argc, char** argv ) {
MPI_Init( &argc, &argv );
int rank, size;
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
MPI_Finalize();
return 0; }
- See the name conventions and the call-by-pointer policy. 查看名称约定和按指针调用的策略
- Compare to OpenMP which offers exactly these two operations as well.
- Different to OpenMP, we will however need ranks all the time, as we have to specify senders and receivers. 始终需要排名 必须指定发送者和接收者。
- For the time being, rank is a continuous numbering starting from 0.
MPI Environment Management
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include "mpi.h" // required MPI include file
#include <stdio.h>
int main(int argc, char *argv[]) {
int numtasks, rank, len, errorcode;
char hostname[MPI_MAX_PROCESSOR_NAME];
// initialize MPI
MPI_Init(&argc,&argv);
// get number of tasks MPI_Comm_size(MPI_COMM_WORLD,&numtasks);
// get my rank
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
// this one is obvious
MPI_Get_processor_name(hostname, &len);
printf ("Number of tasks= %d My rank= %d Running on %s\n", numtasks,rank,hostname);
// MPI_Abort(MPI_COMM_WORLD, errorcode); // done with MPI
MPI_Finalize();
return 0;
}
Concept of building block
- Content
- How does MPI initialise/shutdown
- How to compile MPI codes
- Find out local SPMD instance’s rank and the global size
- MPI conventions
- Expected Learning Outcomes
- The student knows the framework of an mpi application, can compile it and can run it
- The student can explain the terms rank and size
- The student can identify MPI conventions at hands of given source codes
Peer-to-peer Message Passing
- The Message Passing of MPI is (largely) borne by two functions: 消息传递
MPI_SendMPI_Recv
- Which interact through coordination across distinct processes.
1
2
3
4
// on rank from
MPI_Send(&data, count, MPI_INT, to, tag, MPI_COMM);
// on rank to
MPI_Recv(&data, count, MPI_INT, from, tag, MPI_COMM);
- Most of the hard work of parallelising with MPI is managing the Sends and
Recvs consistently. 大部分使用 MPI 进行并行化的辛苦工作是始终管理发送和Recv。 - Today we’ll focus on the blocking versions of these calls. 调用的阻塞版本
Send
1
2
3
4
int MPI_Send(
const void *buffer, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm
)
bufferis a pointer to the piece of data you want to send away. 向您想发送的数据片段的指针countis the numer of itemsdatatype… self-explaining 自解释destis the rank (integer) of the destination node 目标节点的等级(整数)commis the so-called communicator通讯者 (alwaysMPI_COMM_WORLDfor the time being)- Result is an error code, i.e. 0 if successful (UNIX convention)
Blocking:
MPI_Sendis called blocking as it terminates as soon as you can reuse the buffer, i.e. assign a new value to it, without an impact on MPI.被称为阻塞,因为一旦您可以重新使用缓冲区,即为其分配新值,而不会对 MPI 产生影响,它就会终止
Receive
1
2
3
4
5
int MPI_Recv(
void *buffer, int count, MPI_Datatype datatype,
int source, int tag, MPI_Comm comm,
MPI_Status *status
)
bufferis a pointer to the variable into which the received data shall be stored.countis the numer of itemsdatatype…self-explainingdestis the rank (integer) of the source node (may beMPI_ANY)commis the so-called communicator (alwaysMPI_COMM_WORLDfor the time being)statusis a pointer to an instance ofMPI_Statusand holds meta informationstatus是指向MPI_Status实例的指针,并保存元信息- Result is an error code, i.e. 0 if successful (UNIX convention)
Blocking:
MPI_Recvis calledblockingas it terminates as soon as you can read the buffer, i.e. MPI has written the whole message into this variable.
Blocking communication
Blocking:
MPI_Sendis calledblockingas it terminates as soon as you can reuse the buffer, i.e. assign a new value to it, without an impact on MPI.阻塞:
MPI_Send被称为blocking,因为一旦您可以重新使用缓冲区,即为其分配新值,而不会影响 MPI,它就会终止。
Blocking:
MPI_Recvis calledblockingas it terminates as soon as you can read the buffer, i.e. MPI has written the whole message into this variable.阻塞:
MPI_Recv被称为blocking,因为一旦您可以读取缓冲区,即 MPI 已将整个消息写入此变量,它就会终止。
- If a blocking operation returns, it does not mean that the corresponding message has been received. 如果阻塞操作返回,这并不意味着相应的消息已被接收
- Blocking and asynchronous or synchronous execution have nothing to do with each other though a blocking receive never returns before the sender has sent out its data. 阻塞和异步或同步执行之间没有任何关系,尽管阻塞接收在发送方发送数据之前永远不会返回。
- If a blocking send returns, the data must have been copied to the local network chip.
The term blocking just refers to the safety of the local variable. 术语“blocking”只是指本地变量的安全性。
- With blocking sends, you never have a guarantee that the data has been received, i.e. blocking sends are not synchronised. 使用阻塞发送,您永远无法保证数据已经接收,即阻塞发送不是同步的。
From Mathematics and Computer Science (MCS) at Argonne National Lab (ANL):
MPI has a number of different ”send modes.” These represent different choices of buffering (where is the data kept until it is received) and synchronization (when does a send complete). In the following, I use ”send buffer” for the user-provided buffer to send.
[…] Note that ”nonblocking” refers ONLY to whether the data buffer is available for reuse after the call. No part of the MPI specification, for example, mandates concurrent operation of data transfers and computation.
MPI Datatypes
Datatypes: Note that the basic C datatypes are not allowed in MPI calls—MPI wraps (some of) these and you must use the MPI wrapper types in MPI calls.
数据类型:请注意,基本的 C 数据类型在 MPI 调用中是不允许的—MPI 封装了(部分)这些数据类型,您必须在 MPI 调用中使用 MPI 封装类型。
1
2
3
4
5
6
MPI_CHAR
MPI_SHORT
MPI_INT
MPI_LONG
MPI_FLOAT
MPI_DOUBLE
- There are more data types predefined.
- However, I’ve never used others than these.
- Note that there is no bool (C++) before MPI-2.
- In theory, heterogeneous hardware supported.
- Support for user-defined data types and padded arrays.
First code
What are the values of a and b on rank 2?
1
2
3
4
5
6
7
8
9
10
11
12
13
if (rank==0) {
int a=0;
MPI_Send(&a, 1, MPI_INT, 2, 0, MPI_COMM_WORLD);
a=1;
MPI_Send(&a, 1, MPI_INT, 2, 0, MPI_COMM_WORLD);
}
if (rank==2) {
MPI_Status status;
int a;
MPI_Recv(&a, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
int b;
MPI_Recv(&b, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, &status);
}
MPI messages from one rank never overtake.
为什么消息不会乱序?
在 MPI 中,从同一个发送者到同一个接收者的消息绝不会乱序(消息传递的顺序保证),因为:
- 消息严格按顺序到达
- 如果发送端按顺序调用
MPI_Send,接收端按顺序调用MPI_Recv,接收到的值一定和发送顺序一致。
- 如果发送端按顺序调用
- 单个通信路径的顺序性
- 对于来自同一个
rank的消息,MPI 底层会确保消息的顺序性。
- 对于来自同一个
- 消息严格按顺序到达
Why is this called SPMD?
SPMD 是并行编程的一种模型,全称为单程序多数据。它的特点是:
- 单一程序
- 只有一份代码,但根据进程的
rank值,程序的行为可能不同(如本代码中rank==0和rank==2的逻辑不同)。
- 只有一份代码,但根据进程的
- 多数据并行
- 每个 MPI 进程有自己独立的地址空间和数据。不同的进程可以处理不同的数据或接收不同的消息。
在本代码中:
- 所有 MPI 进程运行相同的程序代码。
- 根据
rank的值决定执行哪部分逻辑(条件分支if (rank == 0)和if (rank == 2))。 - 这正是 SPMD 模型的体现。
- 单一程序
Other blocking Sends
- MPI Send is effectively the simplest, but not the only, option for Sending blocking peer-to-peer messages.
- Others include:
- MPI_Ssend — Synchronous, blocking, send
- MPI_Bsend — asynchronous, blocking, Buffered send
- MPI_Rsend — Ready blocking send
MPI_Sendis buffered if the message fits in the MPI-managed buffer (likeMPI_Bsend), otherwise synchronous (likeMPI_Ssend)MPI_Send如果消息适合于 MPI 管理的缓冲区,则进行缓冲,否则同步进行(如MPI_Ssend)MPI_Rsendrequires the recipient to have already calledMPI_Recv
Usage: MPI Recv is always synchronous—it waits until the buffer is filled up with the complete received message. MPI Recv 始终是同步的-它会等待直到缓冲区被完整接收的消息填满。
Excursus/addendum: Buffered sends
1
2
3
4
5
6
7
int bufsize;
char *buf = malloc(bufsize);
MPI_Buffer_attach( buf, bufsize );
...
MPI_Bsend( /*... same as MPI_Send ...*/ );
...
MPI_Buffer_detach( &buf, &bufsize );
- If you use many tags, many blocking commands, and so forth, you stress your system buffers (variables, MPI layer, hardware)
- This might lead to deadlocks though your code semantically is correct
- MPI provides a send routine that buffers explicitly:
MPI_Bsend MPI_Bsendmakes use of a user-provided buffer to save any messages that can not be immediately sent.- Buffers explicitly have to be added to MPI and removed at program termination.
- The
MPI_Buffer_detachcall does not complete until all messages are sent.
Concept of building block
- Content
- Study MPI send and receive
- Discuss term blocking
- Introduce predefined data types
- Study a simple MPI program
- Expected Learning Outcomes
- The student knows signature and semantics of MPI’s send and receive
- The student knows the predefined MPI data types
- The student can explain the term blocking
- The student can write down a simple correct MPI program (incl. the initialisation and the shutdown)
- Material & further reading
- Gropp et al.: Tutorial on MPI: The Message-Passing Interface https://www.mcs.anl.gov/research/projects/mpi/tutorial/gropp/talk.html
MPI tags
Tag: A tag is a meta attribute of the message when you send it away. The receive command can filter w.r.t. tags.
Message arrival: Two MPI messages with the same tag may not overtake.
- With tags, we can make messages overtake each other.
- Tags are typically used to distinguish messages with different semantics.
- Tags are arbitrary positive integers. There is no need to explicitly register them.
- Extreme scale: Too many tags might mess up MPI implementation.
- For sends, real tag is mandatory. Receives may use
MPI_ANY_Tag(wildcard).
Example 1/3
The following snippet shall run on a rank p0:
1
2
3
4
5
6
int a=1;
int b=2;
int c=3;
MPI_Send(&a,1,MPI_INT,p1,0,MPI_COMM_WORLD);
MPI_Send(&b,1,MPI_INT,p1,0,MPI_COMM_WORLD);
MPI_Send(&c,1,MPI_INT,p1,1,MPI_COMM_WORLD);
The following snippet shall run on a rank p1:
1
2
3
4
5
6
int u;
int v;
int w;
MPI_Recv(&u,1,MPI_INT,p0,0,MPI_COMM_WORLD,&status);
MPI_Recv(&v,1,MPI_INT,p0,0,MPI_COMM_WORLD,&status);
MPI_Recv(&w,1,MPI_INT,p0,0,MPI_COMM_WORLD,&status);
What is the value of u,v,w on rank p1?
dead lock or error 等不到tag = 1
Example 2/3
The following snippet shall run on a rank p0:
1
2
3
4
5
6
int a=1;
int b=2;
int c=3;
MPI_Send(&a,1,MPI_INT,p1,0,MPI_COMM_WORLD);
MPI_Send(&b,1,MPI_INT,p1,0,MPI_COMM_WORLD);
MPI_Send(&c,1,MPI_INT,p1,1,MPI_COMM_WORLD);
The following snippet shall run on a rank p1:
1
2
3
4
5
6
int u;
int v;
int w;
MPI_Recv(&u,1,MPI_INT,p0,0,MPI_COMM_WORLD,&status);
MPI_Recv(&v,1,MPI_INT,p0,1,MPI_COMM_WORLD,&status);
MPI_Recv(&w,1,MPI_INT,p0,0,MPI_COMM_WORLD,&status);
What is the value of u,v,w on rank p1?
1 3 2
Example 3/3
The following snippet shall run on a rank p0:
1
2
3
4
5
6
int a=1;
int b=2;
int c=3;
MPI_Send(&a,1,MPI_INT,p1,2,MPI_COMM_WORLD);
MPI_Send(&b,1,MPI_INT,p1,1,MPI_COMM_WORLD);
MPI_Send(&c,1,MPI_INT,p1,0,MPI_COMM_WORLD);
The following snippet shall run on a rank p1:
1
2
3
4
5
6
int u;
int v;
int w;
MPI_Recv(&u,1,MPI_INT,p0,0,MPI_COMM_WORLD,&status);
MPI_Recv(&v,1,MPI_INT,p0,1,MPI_COMM_WORLD,&status);
MPI_Recv(&w,1,MPI_INT,p0,2,MPI_COMM_WORLD,&status);
What is the value of u,v,w on rank p1?
3 2 1
| 示例 | 发送顺序(p0) | 接收顺序(p1) | 结果(u,v,w) |
|---|---|---|---|
| Example 1/3 | a=1, b=2 (Tag=0), c=3 (Tag=1) | 全部接收 Tag=0 消息 | 未定义(缺少第三条消息) |
| Example 2/3 | a=1 (Tag=0), b=2 (Tag=0), c=3 (Tag=1) | 接收顺序:Tag=0, Tag=1, Tag=0 | u=1, v=3, w=2 |
| Example 3/3 | a=1 (Tag=2), b=2 (Tag=1), c=3 (Tag=0) | 接收顺序:Tag=0, Tag=1, Tag=2 | u=3, v=2, w=1 |
A communication classic: Data exchanged in a grid
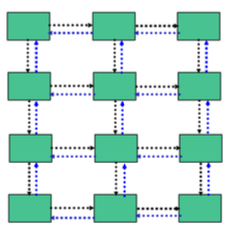
Solution 1: Send everything out (blocking), receive everything blocking I ⇒ High pressure on MPI’s buffers
Solution 2: Split up communication into four phases (up, down, left, right) I ⇒ reduce pressure on communication subsystem
Solution 3: Use four different tags and use MPI ANY as source ⇒ Use tags to identify semantics but receive in same order subsystem delivers messages
Concept of building block
- Content
- Introduce definition of a tag
- Make definition of not-overtaking explicit and study usage
- Introduce buffered sends
- Expected Learning Outcomes
- The student knows definition of tags
- The student can explain their semantics w.r.t. message arrival
- The student can use tags in MPI statements