HPC Session 06 Non-blocking P2P communication
Non-blocking P2P communication
Buffers
MPI distinguishes different types of buffers:
variables
- user-level buffers
- hardware/system buffers
MPI implementations are excellent in tuning communication, i.e. avoid copying, but we have to assume that a message runs through all buffers, then through the network, and then bottom-up through all buffers again. This means that Send and Recv are expensive operations.
Even worse, two concurrent sends might deadlock (but only for massive message counts or extremely large messages). 两个并发发送可能会发生死锁
⇒ One way to deal with this is to allow MPI to optimize the messaging by giving both Send and Recv commands simultaneously — this is a MPI_Sendrecv. 允许 MPI 通过同时给出发送和接收命令来优化消息传递
Sendrecv
1
2
3
4
5
6
7
8
9
int MPI_Sendrecv(
const void *sendbuf, int sendcount,
MPI_Datatype sendtype,
int dest, int sendtag,
void *recvbuf, int recvcount,
MPI_Datatype recvtype,
int source, int recvtag,
MPI_Comm comm, MPI_Status *status
)
- Shortcut for send followed by receive 发送后接收的快捷方式
- Allows MPI to optimise aggressively 积极优化
Anticipates that many applications have dedicated compute and data exchange phases 预计许多应用程序都有专门的计算和数据交换阶段
⇒ Does not really solve our efficiency concerns, just weaken them
MPI_Sendrecv example
We have a program which sends an nentries-length buffer between two processes:
1
2
3
4
5
6
7
if (rank == 0) {
MPI_Send(sendbuf, nentries, MPI_INT, 1, 0, ...);
MPI_Recv(recvbuf, nentries, MPI_INT, 1, 0, ...);
} else if (rank == 1) {
MPI_Send(sendbuf, nentries, MPI_INT, 0, 0, ...);
MPI_Recv(recvbuf, nentries, MPI_INT, 0, 0, ...);
}
- Recall that MPI Send
- behaves like
MPI_Bsendwhen buffer space is available, 缓冲区空间可用 - and then behaves like
MPI_Ssendwhen it is not. 不可用
- behaves like
1
2
3
4
5
6
7
if (rank == 0) {
MPI_Sendrecv(sendbuf, nentries, MPI_INT, 1, 0, /* Send */
recvbuf, nentries, MPI_INT, 1, 0, /* Recv */ ...);
} else if (rank == 1) {
MPI_Sendrecv(sendbuf, nentries, MPI_INT, 0, 0, /* Send */
recvbuf, nentries, MPI_INT, 0, 0, /* Recv */ ...);
}
Nonblocking P2P communication
- Non-blocking commands start with I (immediate return, e.g.)
- Non-blocking means that operation returns immediately though MPI might not have transferred data (mightnot even have started) 非阻塞意味着操作立即返回,尽管 MPI 可能尚未传输数据(甚至可能尚未开始)
- Buffer thus is still in use and we may not overwrite it 不能覆盖buffer
- We explicitly have to validate whether message transfer has completed before we reuse or delete the buffer 需要验证消息传输是否已完成,然后才能重用或删除缓冲区
1 2 3 4 5 6 7
// Create helper variable (handle) int a = 1; // trigger the send // do some work // check whether communication has completed a = 2; ...
⇒ We now can overlap communication and computation.
Why non-blocking. . . ?
- Added flexibility of separating posting messages from receiving them. ⇒ MPI libraries often have optimisations to complete sends quickly if the matching receive already exists. 增加收发消息灵活性,若接收方已存在,库会进行优化以快速完成发送
- Sending many messages to one process, which receives them all. . . 接收所有
1
2
3
4
5
6
7
8
9
int buf1, buf2;
// ...
for (int k=0; k<100; k++){
if (rank==0){
MPI_Recv(&buf2, 1, MPI_INT, k, k, COMM, &status);
}else{
MPI_Send(&buf1, 1, MPI_INT, 0, k, COMM);
}
}
- The receiving process waits on each
MPI_Recvbefore moving on, because it is blocking. - If we used a non-blocking
MPI_Irecv, then all can complete as eachMPI_Sendarrives and we just need toMPI_Waitfor the results.
Isend & Irecv
- Non-blocking variants of
MPI_SendandMPI_Recv非阻塞变体 - Returns immediately, but buffer is not safe to reuse 立即返回,但缓冲区不安全可重用
1
2
3
4
int MPI_Isend(const void *buffer, int count, MPI_Datatype dtype,
int dest, int tag, MPI_Comm comm, MPI_Request *request);
int MPI_Irecv(void *buffer, int count, MPI_Datatype dtype,
int dest, int tag, MPI_Comm comm, MPI_Request *request);
- Note the
requestin the send, and the lack of status in recv - We need to process that
requestbefore we can reuse the buffers 我们需要在重用缓冲区之前处理request
Isend
1
2
3
4
5
6
7
8
9
int MPI_Send(const void *buffer, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm
);
int MPI_Isend(const void *buf, int count, MPI_Datatype datatype,
int dest, int tag, MPI_Comm comm,
MPI_Request *request
);
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status);
int MPI_Wait(MPI_Request *request, MPI_Status *status);
- Pass additional pointer to object of type MPI Request.
- Non-blocking, i.e. operation returns immediately.
- Check for send completition with
MPI_WaitorMPI_Test. 检查发送状况 MPI_Irecvanalogous. 相似- The status object is not required for the receive process, as we have to hand it over to wait or test later. 状态对象不需要用于接收过程,因为我们必须将其交给等待或测试。
Testing
If we have a request, we can check whether the message it corresponds to has been completed with MPI_Test:
1
int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status);
flagwill be true (anintof value 1) if the provided request has been completed, and false otherwise.- true - completed
- false - not
- If we don’t want to test for completion, we can instead
MPI_Wait. . .
Waiting. . .
1
2
3
4
5
6
7
8
9
10
11
MPI_Request request1, request2;
MPI_Status status;
int buffer1[10]; int buffer2[10];
MPI_Send(buffer1, 10, MPI_INT, right, 0, MPI_COMM_WORLD);
MPI_Recv(buffer2, 10, MPI_INT, left, 0, MPI_COMM_WORLD, &status);
buffer2[0] = 0;
MPI_Isend(buffer2, 10, MPI_INT, right, 0, MPI_COMM_WORLD, &request1);
MPI_Irecv(buffer1, 10, MPI_INT, left, 0, MPI_COMM_WORLD, &request2);
buffer1[0] = 0;
There is an error in this code, what change do we need to make for it to be correct? Before buffer1[0] = 0;:
1
2
MPI_Wait(&request1, &status);
MPI_Wait(&request2, &status);
P2P communication in action
1
2
3
4
5
6
7
8
9
10
11
12
13
14
MPI_Request request1, request2;
MPI_Status status;
int buffer1[10]; int buffer2[10];
// Variant A
MPI_Recv(buffer1, 10, MPI_INT, left, 0, MPI_COMM_WORLD, &status);
MPI_Send(buffer2, 10, MPI_INT, right, 0, MPI_COMM_WORLD);
// Variant B
//MPI_Send(buffer2, 10, MPI_INT, right, 0, MPI_COMM_WORLD);
//MPI_Recv(buffer1, 10, MPI_INT, left, 0, MPI_COMM_WORLD, &status);
// Variant C
//MPI_Irecv(buffer1, 10, MPI_INT, left, 0, MPI_COMM_WORLD, &request1);
//MPI_Isend(buffer2, 10, MPI_INT, right, 0, MPI_COMM_WORLD, &request2);
//MPI_Wait(&request1, &status);
//MPI_Wait(&request2, &status);
Does Variant A deadlock? Yes!
MPI_Recvis always blocking. (always waiting)Does Variant B deadlock? Not for only 10 integers (if not too many messages sent before). 若消息数量大 会死锁
Does Variant C deadlock? Is it correct? Is it fast? May we add additional operations before the first wait? – does not dead lock. fast
but may not correct正确的 所指的buffer不一致为什么 Variant C 正确?
1. 不同缓冲区不会冲突
- 在
MPI_Irecv和MPI_Isend中,分别使用了两个独立的缓冲区:buffer1和buffer2。 MPI_Irecv的接收缓冲区buffer1不会与MPI_Isend的发送缓冲区buffer2发生冲突,因此这两个操作可以同时进行。
2.
MPI_Wait确保操作完成MPI_Wait(&request1, &status):确保MPI_Irecv操作完成,表示接收的数据已安全存储到buffer1中。MPI_Wait(&request2, &status):确保MPI_Isend操作完成,表示发送的数据已安全送出。- 因为
Wait是针对具体的request操作的,所以它们分别管理接收和发送,不会冲突。
3. 不存在死锁
- 非阻塞通信不会因为等待数据而卡住程序执行(不像
MPI_Recv和MPI_Send可能相互等待)。 - 即使双方的进程(
left和right)都在进行类似的非阻塞通信操作,因为这些操作独立完成并由Wait同步,整体逻辑上不会死锁。
- 在
Concept of building block
- Content
- Introduce
sendrecv - Introduce concept of non-blocking communication
- Study variants of P2P communication w.r.t. blocking and call order
- Introduce
- Expected Learning Outcomes
- The student knows difference of blocking and non-blocking operations
- The student can explain the idea of non-blocking communication
- The student can write MPI code where communication and computation overlap
Definition: collective
Collective operation: A collective (MPI) operation is an operation involving many/all nodes/ranks.
集体操作:集体(MPI)操作是涉及许多/所有节点/排名的操作。
- In MPI, a collective operation involves all ranks of one communicator (introduced later)
- For
MPI_COMM_WORLD, a collective operation involves all ranks - Collectives are blocking (though newer (>=3.1) MPI standard introduces non-blocking collectives)
- Blocking collectives always synchronise all ranks, i.e. all ranks have to enter the same collective instruction before any rank proceeds 同步所有等级,即所有等级必须在任何等级继续之前输入相同的集合指令
A (manual) collective
1
2
3
4
5
6
7
8
9
10
double a;
if (myrank==0) {
for (int i=1; i<mysize; i++) {
double tmp;
MPI_Recv(&tmp,1,MPI_DOUBLE, ...);
a+=tmp;
}
}
else {
MPI_Send(&a,1,MPI_DOUBLE,0, ...);
What type of collective operation is realised here? (a ???)
1
2
3
double globalSum;
MPI_Reduce(&a, &globalSum, 1,
MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
Flavours of collective operations in MPI
| Type of collective | One-to-all | All-to-one | All-to-all |
|---|---|---|---|
| Synchronisation | Barrier | ||
| Communication | Broadcast, Scatter | Gather | Allgather |
| Computation | Reduce | Allreduce |
Insert the following MPI operations into the table (MPI prefix and signature neglected):
- Barrier
- Broadcast
- Reduce
- Allgather
- Scatter 散开
- Gather
- Allreduce
⇒ Synchronisation as discussed is simplest kind of collective operation
Good reasons to use MPI’s collective
Simplicity of code 代码的简介
- Performance through specialised implementations
- Support through dedicated hardware (cf. BlueGene’s three network topologies: clique, fat tree, ring) 专用硬件支持
MPI Barrier
- Simplest form of collective operation — synchronization of all ranks in comm.
最简单的集体操作形式——同步所有通信等级。
- Rarely used:
⇒ MPI Barrier doesn’t synchronize non-blocking calls 不同步非阻塞调用
⇒ Really meant for telling MPI about calls outside MPI, like IO 用于告诉 MPI 关于 MPI 外部调用,比如 IO
1
2
3
4
5
6
7
8
9
int rank, size;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
for ( int ii = 0; ii < size; ++ii ) {
if ( rank == ii ) {
// my turn to write to the file writeStuffToTheFile();
MPI_Barrier(MPI_COMM_WORLD);
}
}
MPI_Bcast & MPI_Scatter
MPI_Bcastsends the contents of a buffer from root to all other processes.将缓冲区的内容从根进程发送到所有其他进程
MPI_Scattersends parts of a buffer from root to different processes.将缓冲区的部分从根进程发送到不同的进程
MPI_Bcastis the inverse ofMPI_Reduce逆操作MPI_Scatteris the inverse ofMPI_Gather
1
2
3
4
5
6
7
8
9
10
11
12
13
MPI_Comm comm;
int array[100];
int root=0;
//...
MPI_Bcast(array, 100, MPI_INT, root, comm);
int gsize, *sendbuf;
int rbuf[100];
//...
MPI_Comm_size(comm, &gsize);
sendbuf = (int *)malloc(gsize*100*sizeof(int));
//...
MPI_Scatter(sendbuf, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
MPI_Reduce & MPI_Gather
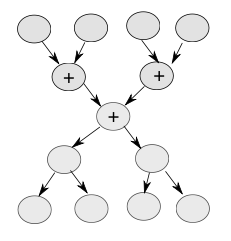
MPI_Reducereduces a value across ranks to a single value on root using a prescribed reduction operator.将跨等级的值减少到根上使用指定的减少运算符的单个值 ?
MPI_Gatherconcatenates the array pieces from all processes onto the root process. 将所有进程的数组片段连接到根进程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
MPI_Comm comm;
int sum, root=0;
//...
MPI_Reduce(sum, c, 1, MPI_INT, MPI_SUM, root, comm);
int gsize,sendarray[100];
int myrank, *rbuf;
//...
MPI_Comm_rank(comm, &myrank);
if (myrank == root) {
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*100*sizeof(int));
}
MPI_Gather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, root, comm);
MPI_Allgather & MPI_Allreduce
MPI_Allgatheris an MPI Gather which concatenates the array pieces on all processes. 将所有进程上的数组片段连接起来MPI_Allreduceis anMPI_Reducewhich reduces on all processes. 一个在所有进程上进行减少的MPI_Reduce
1
2
3
4
5
6
7
8
9
10
11
MPI_Comm comm;
int sum, root=0;
//...
MPI_Allreduce(sum, c, 1, MPI_INT, MPI_SUM, comm);
int gsize,sendarray[100];
int *rbuf;
//...
MPI_Comm_size(comm, &gsize);
rbuf = (int *)malloc(gsize*100*sizeof(int));
MPI_Allgather(sendarray, 100, MPI_INT, rbuf, 100, MPI_INT, comm);
MPI_Allgatheris used a lot (for better or worse) debugging distributed arrays — serial checks work on one process!MPI_AllreduceIs particularly useful for convergence checks — we will see this when we return to the Jacobi iteration problem in MPI.
Concept of building block
- Content
- Classify different collectives from MPI
- Understand use cases for main forms of MPI collectives
- Expected Learning Outcomes
- The student knows which type of collectives do exist (*)
- The student can explain what collectives do (*)
- The student can identify collective code fragments (*)
- The student can use collectives or implement them manually