IML L5.2 Variance Bias Trade-off
Variance Bias Trade-off
What is Bias and Variance?
Bias: The error introduced by approximating a real-world problem, which may be complex, by a much simpler model.
- High bias can cause an algorithm to miss relevant relations between features and target outputs (underfitting).
Variance: The error introduced by the model’s sensitivity to fluctuations in the training set.
- High variance can cause overfitting, where the model captures noise in the data.
Let’s suppose the relationship between $X$ and $Y$ is described by
\[{Y=\sum_{i}w_{i}^{\star}x^{i}+\epsilon}\]where $w_i^\star$ are the true parameters and $\epsilon$ is some noise.
We will try to model this with
\[y=p(x)=\sum_iw_ix^i\]where now the $w_i$ will be fitted to data.
We define
\[{w_i~=~\langle w_i\rangle}\]as the expectation value of the parameter $w_i$ when fitted to multiple independent samples drawn from the true distribution.
We want to calculate the expected deviation of the fitted coefficients form the true coefficient:
\[\langle({w_{i}}-{w^\star_{i}})^{2}\rangle\\\langle({w_{i}}-{w^\star_{i}})^{2}\rangle=\langle({w_{i}}-{w_{i}}+{w_{i}}-{w^\star_{i}})^{2}\rangle\\=\langle({w_{i}}-{w_{i}})^{2}\rangle+\langle({w_{i}}-{w^\star_{i}})^{2}\rangle+2\langle({w_{i}}-{w_{i}})({w_{i}}-{w^\star_{i}})\rangle\]The third term vanishes: \(\langle(w_-w_)(w_-w_^{\star})\rangle=\langle(w_{\mathrm{i}}-w_)\rangle(w_-w_^{\star})=0\)
So we have
\[\langle({w_{i}-w_{i}^{\star}})^{2}\rangle=\langle({w_{i}-w_{i}})^{2}\rangle+\langle({w_{i}-w_{i}^{\star}})^{2}\rangle\]The first term is the variance term and the second is the bias.
Example
To illustrate the variance-bias tradeoff we will be using different models to describe data with true relationship between the input xx and the outcome
\[Y(x)=1+\frac{1}{5}x^{2}+\epsilon\quad for\quad0\leq x\leq1;,\quad0; \mathrm {otherwise}\]Where $\epsilon$ is a gaussian noise. We will use the two models
\[m_1(x) = a+bx\]and
\[m_2(x) = a + bx + cx^2 + dx^3\]Using $m_1$, a model with too few parameters we get
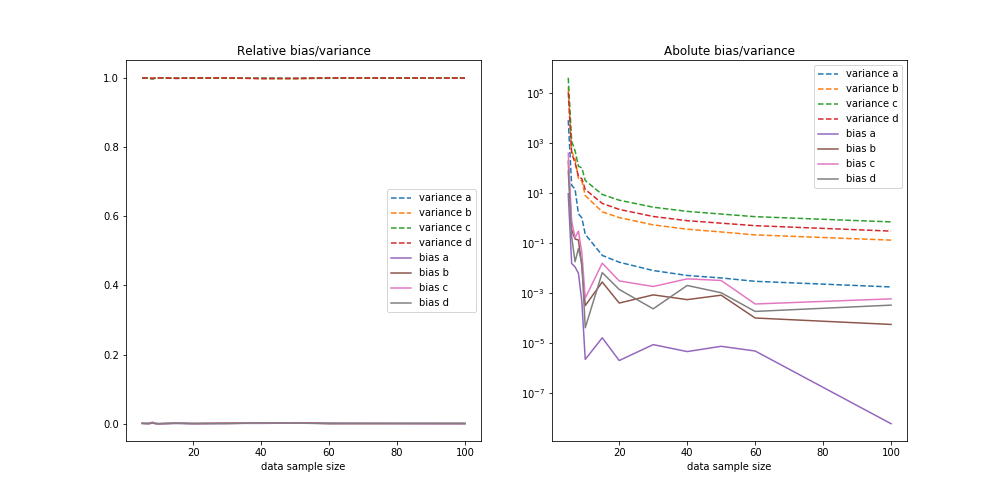
For low dataset size we see the the variance dominates but as the number of training samples grows the bias dominates. Since the model is not capable of describing the truth the error is not diminishing even though the variance part of the error drops proportional to $1/\sqrt N$
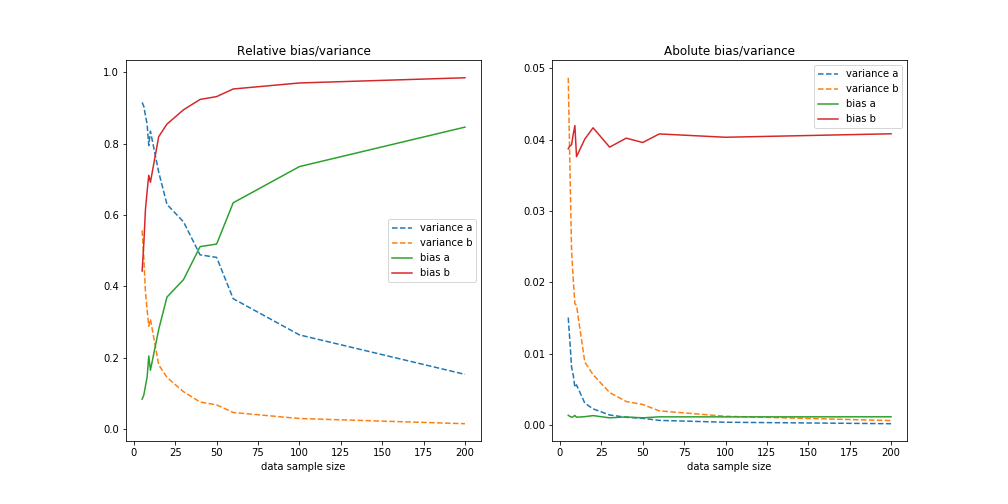
For the second model where we have enough freedom to exactly describe the truth we get: