IML L1.1
IML L1.1
Machine Learing
Machine learning algorithms can be classified according to
- the type of problems they solve
- the model they use
- the way they learn
Types of problems
- classification
- output of the model is a discrete set of categories
- examples:
- spam detection
- pion/proton discrimination
- positive/negative COVID test
- examples:
- output of the model is a discrete set of categories
- regression
- output of the model is a continous variable
- examples:
- value of stock
- country GDP
The boundary between the two types can be blured:
- when the categories have an ordering we can use regression and bin the result into categories
- A*, A, B, C, … grades
- number of stars for a review
- energy rating of a building
- for classification we can fit a function for the probability of belonging to one class
Types of learning
- supervised learning
- we have a training set with labelled examples
- unsupervised learning
- no labelled examples
- model has to find features
- can be used as a first step before supervised learning
- dimensionality reduction
- many features
- need to find the most relevant ones as input to supervised learning model
Learning modes
- batch learning
- online learning
- mini-batch
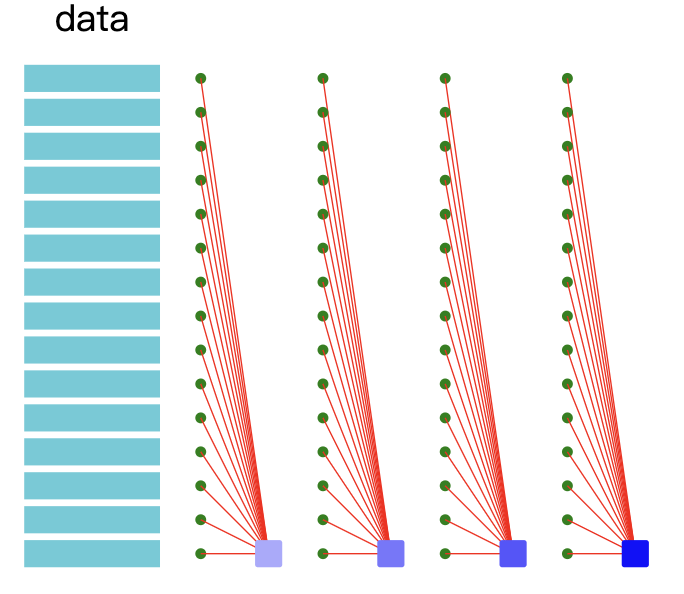
Batch learning
The entire training set is used for each iteration of the model optimisation
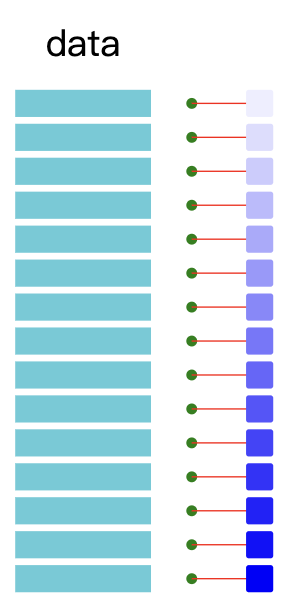
Online learning
The model is updated for each new training example.
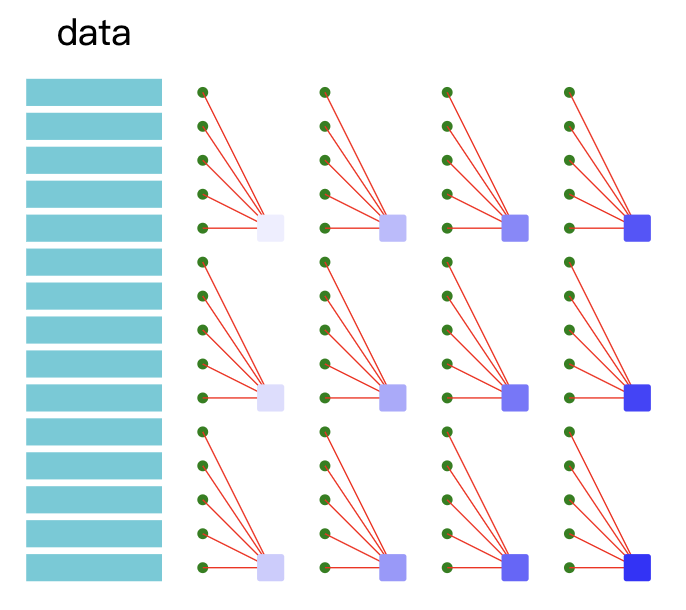
Mini-batch
The model is optimised for subsets of the training set
Instance based vs Model based
- instance based
- uses examples to learn
- need “similarity” measure to compare new data to training data
- model based
- we use a model to quantify the relationship between the data
- the data fixes the parameters of the model
Example: predicting final grade $g_4$ of a student given their 1st, 2nd and 3rd year result $g_1$, $g_2$ and $g_3$.
instance-based:
- look at historical results and find the student who has the closest marks to the student we want to predict the result from
- use the final grade of the past student as the prediction for the new student
- could look at a set of historical students and average
model-based:
- we can hypothesize a linear dependency:
- fit the coefficients $c1$, $c_2$, $c_3$ to historical data and use them to predict the new student’s final grade.
Examples of model-based algorithms
- linear models
- perceptron
- logistic regression
- SVM (support vector machine)
- …
- non-linear models
- polynomial features
- neural networks
- …
Examples of instance-based algorithms
- $k$-neighbour
- SVM with RBF kernel
- …
This post is licensed under CC BY 4.0 by the author.